
TIL 51 (HTTP/1,2,3, git branch)(2021.12.02)
HTTP/1.x의 커넥션 관리 출처
HTTP는 클라이언트와 서버 사이의 커넥션을 제공하는 TCP를 전송프로토콜로 주로 이용합니다. 초기에는, HTTP는 이런 커넥션들을 다루기 위해 단일 모델을 제공했습니다. 요청이 보내져야 할 때마다 커넥션들은 매번 새롭게 생성되었고 응답이 도착한 이후에 연결을 닫는 형태로 단기로만 유지되었습니다.
이러한 방식은 TCP 연결을 열고 닫음으로써 자원을 소비하기 때문에 성능상에 제약을 발생시켰습니다.
HTTP/1.1에서 두 가지 모델이 추가되었습니다.

단기 커넥션
HTTP 본래의 모델이자 HTTP/1.0의 기본 커넥션은 단기 커넥션입니다. 각각의 HTTP 요청은 각각의 커넥션 상에서 실행됩니다. 이는 TCP 핸드 셰이크는 각 HTTP 요청 전에 발생하고, 이들이 직렬화됨을 의미합니다.
TCP 핸드셰이크는 그 자체로 시간을 소모하기는 하지만 TCP 커넥션은 지속적으로 연결되었을 때 부하에 맞춰 더욱 예열되어 더욱 효율적으로 작동합니다. 단기 커넥션들은 TCP의 이러한 효율적인 특성을 사용하지 않게 하며 예열되지 않은 새로운 연결을 통해 지속적으로 전송함으로써 성능이 최적 상태보다 저하됩니다.
이 모델은 HTTP/1.0에서 사용된 기본 모델입니다(Connection 헤더가 존재하지 않거나, 그것의 값이 close로 설정된 경우). HTTP/1.1에서는, 이 모델은 Connection 헤더가 close 값으로 설정되어 전송된 경우에만 사용됩니다.
영속적인 커넥션
단기 커넥션은 두 가지 결점을 지니고 있습니다: 새로운 연결을 맺는데 드는 시간이 상당하다는 것과, TCP기반 커넥션의 성능은 오직 커넥션이 예열된 상태일 때만 나아진다는 것입니다. 이런 문제를 완화시키기 위해, HTTP/1.1보다도 앞서 영속적인 커넥션의 컨셉이 만들어졌습니다. 이는 keep-alive 커넥션이라고 불리기도 합니다.
영속적인 커넥션은 얼마간 연결을 열어놓고 여러 요청에 재사용함으로써, 새로운 TCP 핸드셰이크를 하는 비용을 아끼고, TCP의 성능 향상 기능을 활용할 수 있습니다. 커넥션은 영원히 열려있는지 않으며, 유휴 커넥션들은 얼마 후에 닫힙니다(서버는 Keep-Alive 헤더를 사용해서 연결이 최소한 얼마나 열려있어야 할지를 설정할 수 있습니다).
물론 영속적인 커넥션도 단점을 가지고 있습니다. 유휴 상태일때에도 서버 리소스를 소비하며, 과부하 상태에서는 DoS attacks을 당할 수 있습니다. 이런 경우에는 커넥션이 유휴 상태가 되자마자 닫히는 비영속적 커넥션(non-persistent connections)을 사용하는 것이 더 나은 성능을 보일 수 있습니다.
HTTP/1.0 커넥션은 기본적으로 영속적이지 않습니다. Connection를 close가 아닌 다른 것으로, 일반적으로 retry-after로 설정하면 영속적으로 동작하게 될 겁니다.
반면, HTTP/1.1에서는 기본적으로 영속적이며 헤더도 필요하지 않습니다(그러나 HTTP/1.0으로 동작하는 경우(fallback)에 대비해서 종종 추가하기도 합니다.).
HTTP 파이프라이닝
파이프라이닝이란 같은 영속적인 커넥션을 통해서, 응답을 기다리지 않고 요청을 연속적으로 보내는 기능입니다. 이것은 커넥션의 지연를 회피하고자 하는 방법입니다. 이론적으로는, 두 개의 HTTP 요청을 하나의 TCP 메시지 안에 채워서(be packed) 성능을 더 향상시킬 수 있습니다. HTTP 요청의 사이즈는 지속적으로 커져왔지만, 일반적인 MSS(최대 세그먼트 크기)는 몇 개의 간단한 요청을 포함하기에는 충분히 여유있습니다.
모든 종류의 HTTP 요청이 파이프라인으로 처리될 수 있는 것은 아닙니다: GET, HEAD, PUT 그리고 DELETE 메서드같은 idempotent 메서드만 가능합니다. 실패가 발생한 경우에는 단순히 파이프라인 컨텐츠를 다시 반복하면 됩니다.
오늘날, 모든 HTTP/1.1 호환 프록시와 서버들은 파이프라이닝을 지원해야 하지만, 실제로는 많은 프록시와 서버들은 제한을 가지고 있습니다. 모던 브라우저가 이 기능을 기본적으로 활성화하지 않는 이유입니다.
HTTP/1.1 느린 이유? 출처
- 연결당 하나의 요청과 응답을 처리하기 때문에 동시 전송 문제와 다수의 리소스를 처리하기에 속도와 성능 이유가 존재
- Head Of Line Blocking (특정 응답 지연) - HTTP/1.1 사양의 제한으로 Request의 순서와 Response의 응답순서는 동기화 되야한다. 그렇기 때문에 특청 요청을 처리하는데 많은 시간이 걸린다면 다른 요청을 처리하는데 지연이 발생한다.
- 헤더가 크다 (특히 쿠키때문에) - 매 요청마다 중복되는 헤더를 보내게 되기 때문에 비효율적이다.
HTTP/1.1의 속도 문제를 개선하기 위한 노력
- 이미지 스프라이트 - 다수의 리소스 요청을 보내게되면 HOC Blocking이 발생할 수도 있기 때문에 이미지들을 하나로 합쳐서 리소스 요청을 한 번만 보내는 방식
- CSS/JavaScript 압축
HTTP/2.0
HTTP/2.0은 새로운 기능이 도입되기 보단 HTTP/1.1의 성능을 개선시키는데 많은 노력을 쏟았다. 즉, 성능 향상에 초점을 맞춘 프로토콜입니다.
HTTP/2.0 특징
HTTP Body 이진 데이터
기존 HTTP 는 Body가 문자열로 이루어져 있지만, HTTP 2.0 부터는 binary framing layer 라고 하는 공간에 이진 데이터로 전송됩니다.
HTTP Req Method, 헤더 등은 여전히 문자열로 전송되지만, 밑 바디 부분이 변경되는 것이 가장 큰 변경점 중 하나입니다.
좌측은 HTTP 1.1 로 구성된 메세지이고, 우측은 HTTP 2.0 으로 만들어진 메세지입니다.
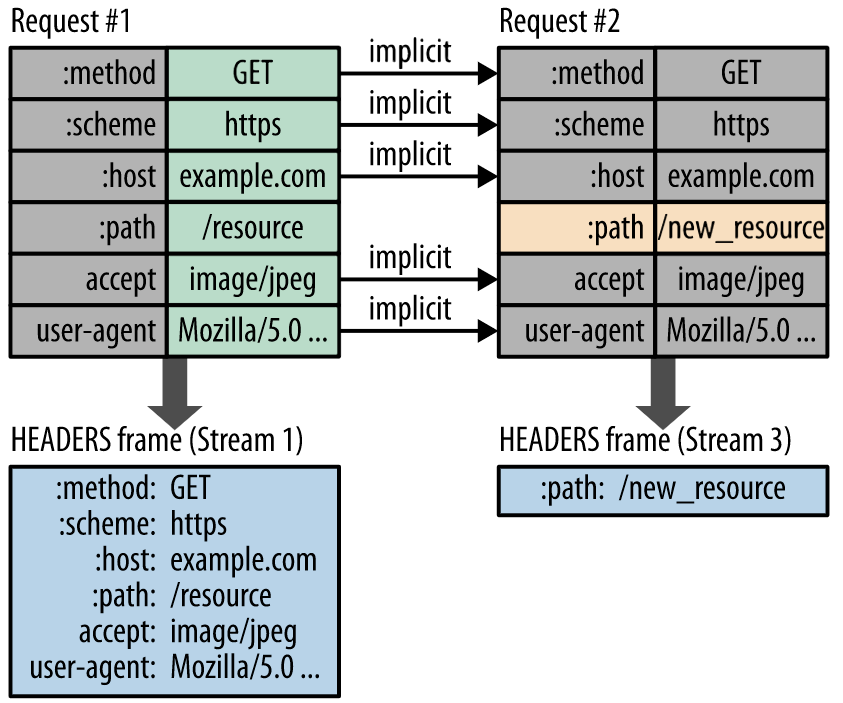
헤더와 바디 프레임으로 나뉘어 들어간다는 것을 알 수 있습니다.
Multiplexed Streams
한 커넥션에서 여러개의 메세지를 주고받을 수 있으며, 응답은 순서에 상관없이 stream으로 주고 받습니다. HTTP/1.1의 Connection Keep-Alive, Pipelining의 개선이라고 볼 수 있습니다.
아래의 이미지 처럼, 하나의 커넥션에서 여러 병렬 스트림(3개)이 존재 할 수 있습니다. stream이 뒤섞여서 전송 될
경우, stream number를 이용해 수신측에서 재조합됩니다.
Server Push
서버는 클라이언트 요청에 대해 요청하지도 않은 리소스를 마음대로 보낼 수 있습니다.
한마디로 클라이언트(브라우저)가 HTML문서를 요청했고 해당 HTML에 여러개의 리소스(CSS, Image 등) 가 포함되어 있는 경우 HTTP/1.1에서 클라이언트는 요청한 HTML문서를 수신한 후 HTML문서를 해석하면서 필요한 리소스를 재요청합니다.
하지만 HTTP/2.0에선 Server Push 기법을 통해서 클라이언트가 요청하지도 않은 (HTML문서에 포함된 리소스) 리소스를 Push 해주는 방법으로 클라이언트의 요청을 최소화 해서 성능 향상을 이끌어 냅니다.
이를 PUSH_PROMISE 라고 부르며 PUSH_PROMISE를 통해서 서버가 전송한 리소스에 대해선 클라이언트는 요청을 하지 않습니다.
Header Compression
Header의 내용과 중복되는 필드를 재전송 하지 않도록 하여, 데이터를 절약합니다. 또한 기존에 HTTP Header가 Plain Text(평문)이었지만, HTTP/2에서는 Hash Table과 Huffman Coding을 사용하는 HPACK이라는 Header 압축방식을 이용하여 데이터 전송 효율을 높였습니다.
HTTP/3 출처
QUIC
Quick UDP Internet Connections 의 약자로, UDP를 기반으로 TCP + TLS + HTTP 의 기능을 모두 구현하는 프로토콜입니다. 구글에서 개발했던 SPDY 기술이 HTTP/2의 기반 기술이었는데 역시 구글에서 개발한 QUIC이 HTTP/3의 기반 기술이 되었습니다.

HTTP/3는 기존의 HTTP/1, HTTP/2와는 다르게 UDP 기반의 프로토콜인 QUIC 을 사용하여 통신하는 프로토콜입니다.
HTTP/3와 기존 HTTP 들과 가장 큰 차이점이라면 TCP가 아닌 UDP 기반의 통신을 한다는 것입니다.
UDP를 사용하지만 그렇다고 기존의 신뢰성 있는 통신이라는 타이틀을 포기한 것은 아닙니다.
구글이 QUIC을 만들 때 UDP를 선택한 이유에는 기존의 TCP를 수정하기가 어려운데다가, 백지 상태나 다름 없는 UDP를 사용함으로써 QUIC의 기능을 확장하기 쉬웠기 때문이라고 합니다.
RTT 감소로인한 지연시간 단축
QUIC은 TCP를 사용하지 않기 때문에 통신을 시작할 때 번거로운 3 Way Handshake 과정을 거치지 않아도 됩니다. 클라이언트가 보낸 요청을 서버가 처리한 후 다시 클라이언트로 응답해주는 사이클을 RTT(Round Trip Time)이라고 하는데, TCP는 연결을 생성하기 위해 기본적으로 1 RTT가 필요하고, 여기에 TLS를 사용한 암호화까지 하려고 한다면 TLS의 자체 핸드쉐이크까지 더해져 총 3 RTT가 필요합니다.
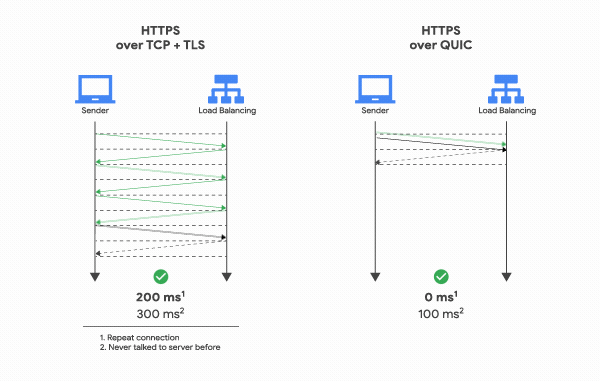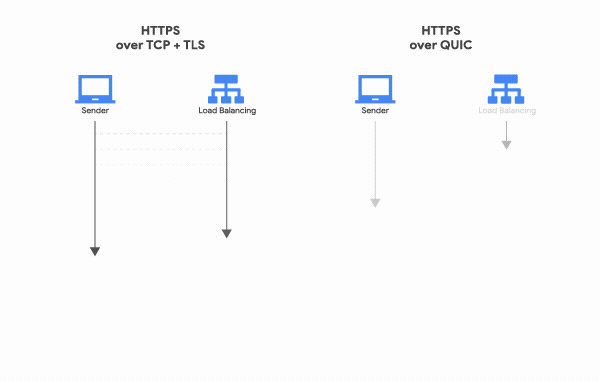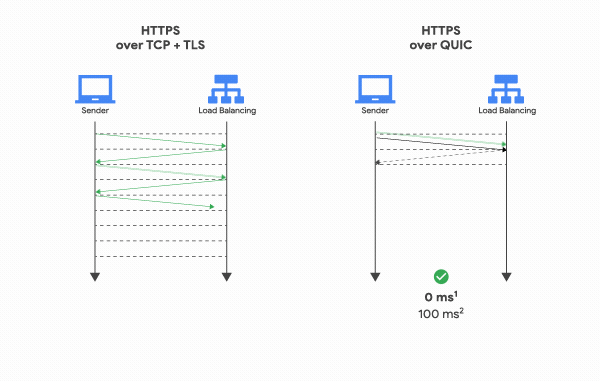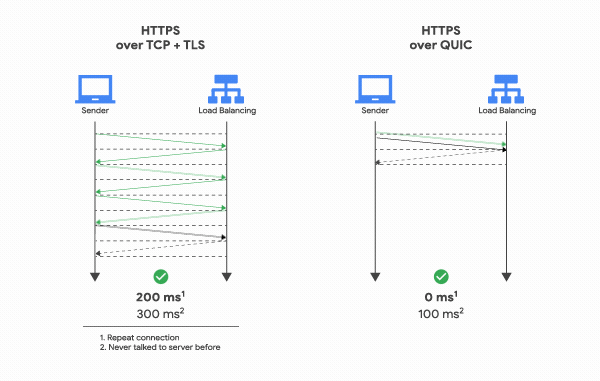
반면 QUIC은 첫 연결 설정에 1 RTT만 소요합니다. 그 이유는 연결 설정에 필요한 정보와 함께 데이터도 보내버리기 때문입니다. 클라이언트가 서버에 어떤 신호를 한번 주고, 서버도 거기에 응답하기만 하면 바로 본 통신을 시작할 수 있다는 것입니다.
단, 클라이언트가 서버로 첫 요청을 보낼 때는 서버의 세션 키를 모르는 상태이기 때문에 목적지인 서버의 Connection ID를 사용하여 생성한 특별한 키인 초기화 키(Initial Key)를 사용하여 통신을 암호화 합니다.
그리고 한번 연결에 성공했다면 서버는 그 설정을 캐싱해놓고 있다가, 다음 연결 때는 캐싱해놓은 설정을 사용하여 바로 연결을 성립시키기 때문에 0 RTT만으로 바로 통신을 시작할 수도 있습니다. 이런 점들 때문에 QUIC은 기존의 TCP+TLS 방식에 비해 지연시간을 더 줄일 수 있었던 것입니다.
TCP Fast Open + TLS 1.3 으로 구현이 되긴하지만 주고 받는 데이터가 큰 경우 QUIC가 유리합니다.
패킷 손실 감지에 걸리는 시간 단축
QUIC도 TCP와 마찬가지로 전송하는 패킷에 대한 흐름 제어를 해야합니다. 통신과정에서 발생한 에러를 재전송을 통해 에러를 복구하는 ARQ 방식을 사용하기 때문입니다.
TCP는 여러 ARQ 방식 중에서 Stop and Wait ARQ 방식을 사용하고 있습니다. 이 방식은 송신 측이 패킷을 보낸 후 타이머를 사용하여 시간을 재고, 일정 시간이 경과해도 수신 측이 적절한 답변을 주지 않는다면 패킷이 손실된 것으로 판단하고 해당 패킷을 다시 보내는 방식입니다.
TCP에서 패킷 손실 감지에 대한 대표적인 문제는 송신 측이 패킷을 수신측으로 보내고 난 후 얼마나 기다려줄 것인가, 즉 타임 아웃을 언제 낼 것인가를 동적으로 계산해야한다는 것입니다. 이때 이 시간을 RTO(Retransmission Time Out)라고 하는데, 이때 필요한 데이터가 바로 RTT(Round Trip Time)들의 샘플들입니다.
한번 패킷을 보낸 후 잘 받았다는 응답을 받을 때 걸렸던 시간들을 측정해서 동적으로 타임 아웃을 정하는 것입니다. 즉, RTT 샘플을 측정하기 위해서는 반드시 송신 측으로 부터 ACK를 받아야하는데, 정상적인 상황에서는 딱히 문제가 없으나 타임 아웃이 발생해서 패킷 손실이 발생하게 되면 RTT 계산이 애매해집니다.
이런 경우를 위해 QUIC는 헤더에 별도의 패킷 번호 공간을 부여해 패킷 고유의 번호를 가지고 있습니다.
TCP의 경우 타임스탬프를 사용할 수 있는 상황이라면 타임스탬프를 통해 패킷의 전송 순서를 파악할 수 있지만, 만약 사용할 수 없는 경우 시퀀스 번호에 기반하여 암묵적으로 전송 순서를 추론할 수 밖에 없습니다.
QUIC는 이런 불필요한 과정을 패킷마다 고유한 패킷 번호를 통해 해결함으로써 패킷 손실 감지에 걸리는 시간을 단축할 수 있었습니다.
멀티플렉싱을 지원
HTTP/3도 HTTP/2와 같은 멀티플렉싱을 지원합니다.
QUIC 또한 HTTP/2와 동일하게 멀티플렉싱을 지원하기 때문에, 이런 이점을 그대로 가져가고 있습니다.
하나의 스트림에서 문제가 발생한다고 해도 다른 스트림은 지킬 수 있게 되어 이런 문제에서 자유로울 수 있습니다.
클라이언트의 IP가 바뀌어도 연결이 유지됨
TCP의 경우 소스의 IP 주소와 포트, 연결 대상의 IP 주소와 포트로 연결을 식별하기 때문에 클라이언트의 IP가 바뀌는 상황이 발생하면 연결이 끊어져 버립니다. 연결이 끊어졌으니 다시 연결을 생성하기 위해 결국 Handshake 과정을 다시 거쳐야한다는 것이고, 이 과정에서 다시 레이턴시가 발생합니다.
(모바일의 경우 Wi-fi , 셀룰러 전환으로 인해 ip 변경이 잦음)
반면 QUIC은 Connection ID를 사용하여 서버와 연결을 생성합니다. Connection ID는 랜덤한 값일 뿐, 클라이언트의 IP와는 전혀 무관한 데이터이기 때문에 클라이언트의 IP가 변경되더라도 기존의 연결을 계속 유지할 수 있습니다. 이는 새로 연결을 생성할 때 거쳐야하는 핸드쉐이크 과정을 생략할 수 있다는 의미입니다.
GIT Branch 종류 (5가지) 출처
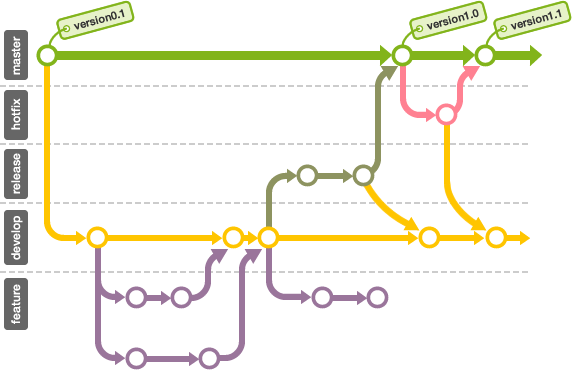
Gitflow Workflow에서는 항상 유지되는 메인 브랜치들(master,develop)과 일정 기간 동안만 유지되는 보조 브랜치들(feature,release,hotfix)을 포함하여 총 5가지의 브랜치를 사용합니다.
Master Branch
제품으로 출시될 수 있는 브랜치
배포(Release) 이력을 관리하기 위해 사용합니다.
즉, 배포 가능한 상태만 관리하는 것입니다.
Develop Branch
다음 출시 버전을 개발하는 브랜치
기능 개발을 위한 브랜치들을 병합하기 위해 사용합니다.
즉, 모든 기능이 추가되고 버그가 수정되어 배포 가능한 안정적인 상태라면 develop 브랜치를 'master' 브랜치에 병합(merge)합니다. 대부분을 이 브랜치를 기반으로 개발을 진행합니다.
Feature branch
기능을 개발하는 브랜치
새로운 기능 개발 및 버그 수정이 필요할 때마다 'develop'브랜치로부터 분기합니다. 기본적으로 공유할 필요가 없기 때문에, 자신의 로컬 저장소에서 관리합니다.
1. develop 브랜치에서 새로운 기능에 대한 feature 브랜치를 분기함
2. 새로운 기능에 대한 작업을 수행
3. 작업이 끝나면 develop 브랜치로 병합(merge)
4. 더 이상 필요하지 않은 feature 브랜치는 삭제
5. 새로운 기능에 대한 feature 브랜치를 중앙 원격 저장소에 올림(push)
Release Branch
이번 출시 버전을 준비하는 브랜치
배포를 위한 전용 브랜치를 사용함으로써 한 팀이 해당 배포를 준비하는 동안 다른팀은 다음 배포를 위한 기능 개발을 계속할 수 있습니다.
Hotfix Branch
출시 버전에서 발생한 버그를 수정하는 브랜치
배포한 버전에 긴급하게 수정을 해야할 필요가 있을경우, 'master'브랜치에서 분기하는 브랜치입니다.